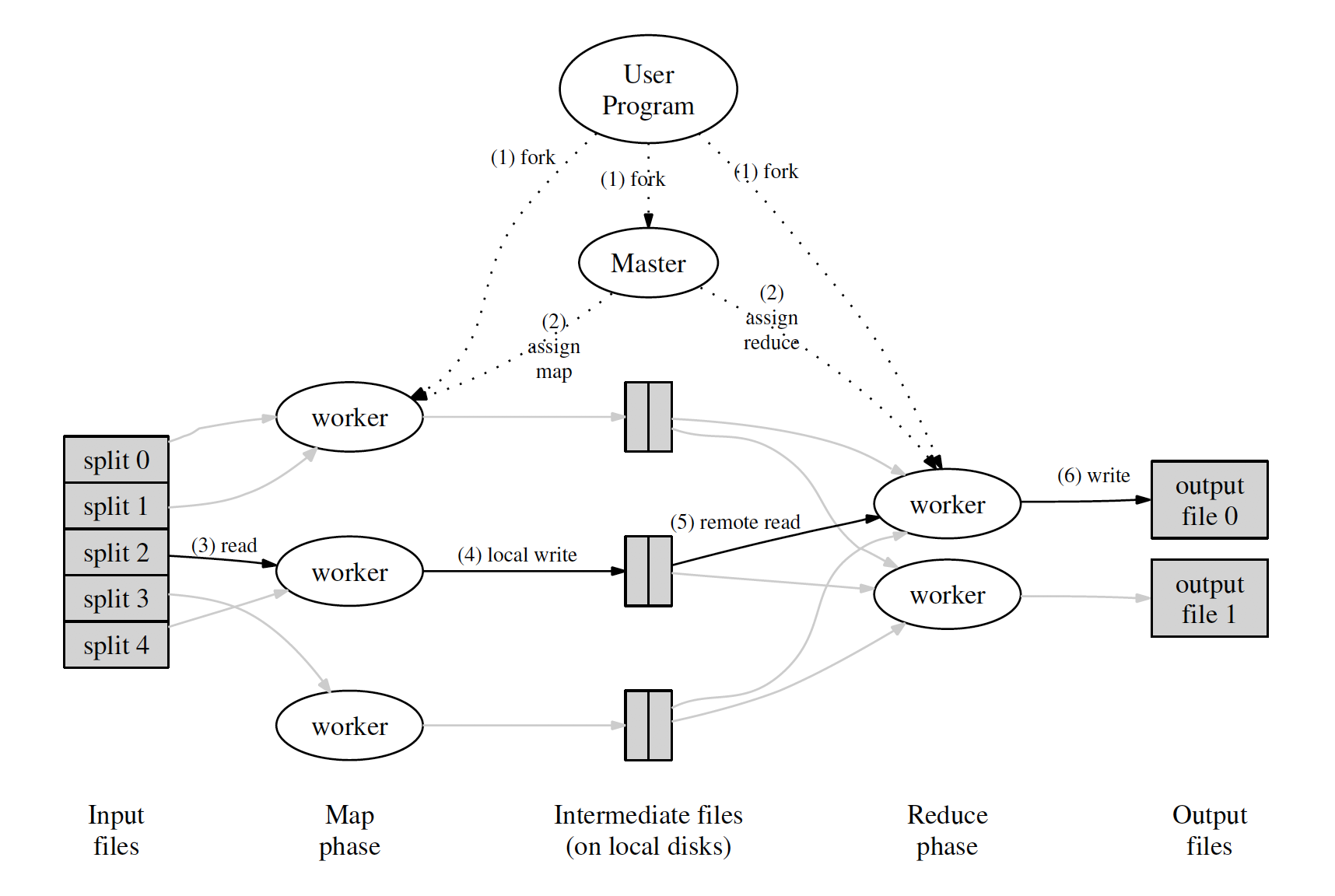
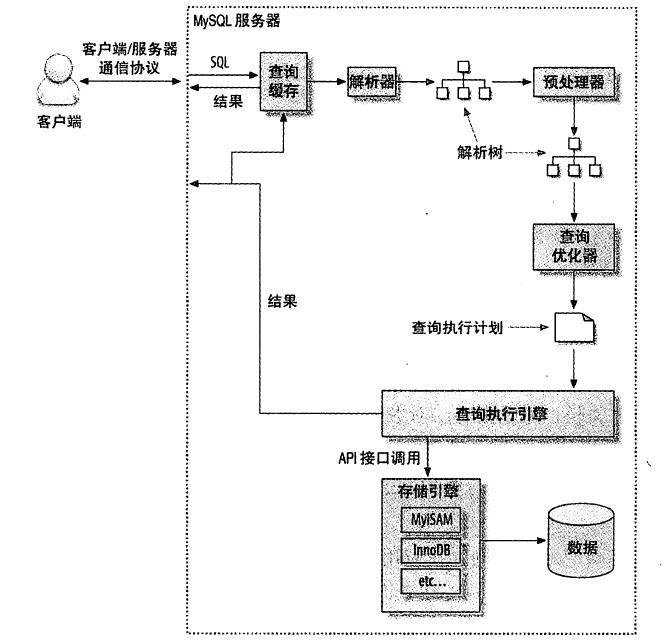
@score.setter defscore(self, value): ifnot isinstance(value, int): raise ValueError('score must be an integer!') if value < 0or value > 100: raise ValueError('score must between 0 ~ 100!') self._score = value
defconsumer(): r = '' whileTrue: n = yield r ifnot n: return print('[CONSUMER] Consuming %s...' % n) r = '200 OK'
defproduce(c): c.send(None) n = 0 while n < 5: n = n + 1 print('[PRODUCER] Producing %s...' % n) r = c.send(n) print('[PRODUCER] Consumer return: %s' % r) c.close()
c = consumer() produce(c)
注意 send(n)为将参数传给yield
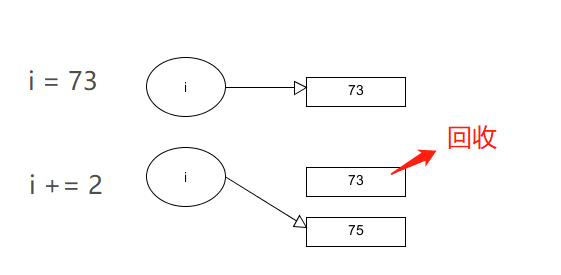
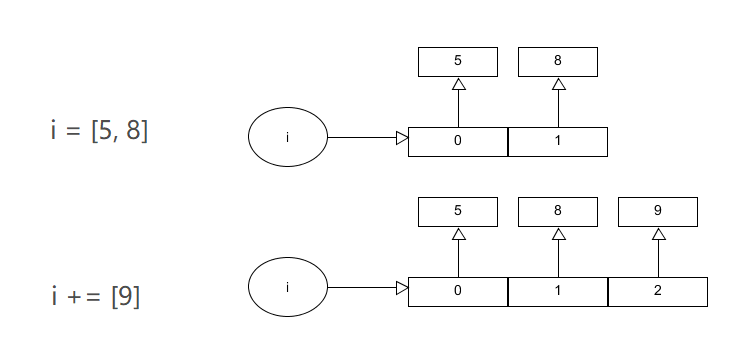
垃圾回收机制
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率
SELECT cust_id, COUNT(*) AS orders FROM orders WHERE prod_price >= 10 GROUPBY vend_id HAING COUNT(*) >= 2
子查询
1 2 3 4 5
SELECT cust_id FROM orders WHERE order_num IN(SELECT order_num FROM orderitems WHERE prod_id = 'TNT2')
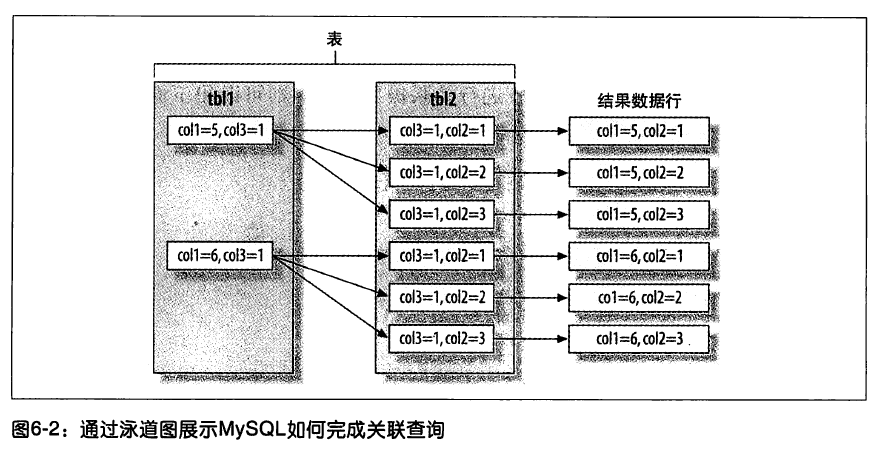
联结表
内部联结
1 2 3
SELECT vend_name, prod_name, prod_price FROM vendors v INNERJOIN products p ON v.vend_id = p.vend_id
创建高级联结
自联结
1 2 3 4
SELECT p1.prod_id, p1.prod_name FROM products AS p1, products AS p2 WHERE p1.vend_id = p2.vend_id AND p2.prod_id = 'DTNTR'
外部联结
包含在相关表中没有关联行的行:OUT JOIN
在使用OUTER JOIN语法时,必须使用RIGHT或LEFT关键字指定包括其所有行的表
LEFT JOIN从左边的表中选择所有行
RIGHT JOIN从右边的表中选择所有行
1 2 3
SELECT customers.cust_id, orders.order_num FROM customers RIGHTOUTERJOIN orders ON orders.cust_id = customers.cust_id
组合查询
合并结果集
在各语句之间放上关键字UNION
1 2 3 4 5 6 7
SELECT vend_id, prod_id, prod_price FROM products WHERE prod_price <= 5 UNION SELECT vend_id, prod_id, prod_price FROM products WHERE vend_id IN (1001, 1002)
SELECT vend_id, prod_id, prod_price FROM products WHERE prod_price <= 5 UNION SELECT vend_id, prod_id, prod_price FROM products WHERE vend_id IN (1001, 1002) ORDERBY vend_id, prod_price
全文本搜索
两个最常使用的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持
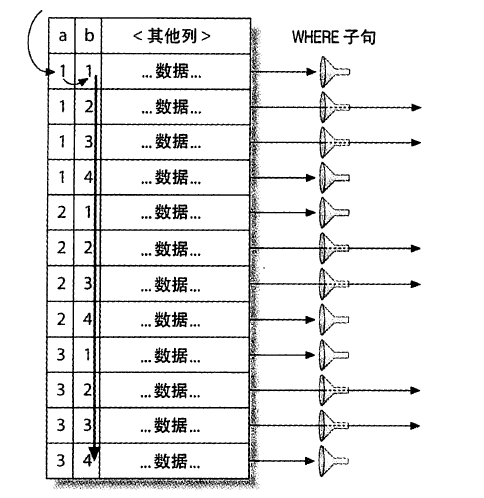
正则搜索的限制:
性能
难以明确控制
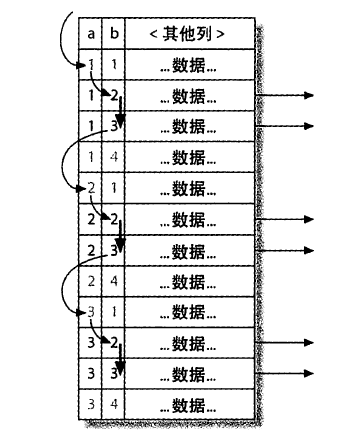
全文本搜索中数据是索引的,所以速度很快
启用全文本搜索支持
在CREATE时FULLTEXT(note_text)
进行全文本搜索
Match()指定被搜索的列,Against()指定要使用的搜索表达式
1 2 3 4 5
SELECT note_text FROM productnotes WHEREMatch(note_text) Against('rabbit') 可以用LIKE WHERE note_text LIKE'%rabbit%'
CREATEPROCEDURE productpricing( OUT pl DECIMAL(8, 2) OUT ph DECIMAL(8, 2) OUT pa DECIMAL(8, 2) ) BEGIN SELECTMIN(prod_price) INTO pl FROM products; SELECTMAX(prod_price) INTO ph FROM products; SELECTAVG(prod_price) INTO pa FROM products; END;
CREATEPROCEDURE processorders() BEGIN DECLARE ordernumbers CURSOR FOR SELECT order_num FROM orders; END;
打开和关闭游标
1 2
OPEN ordernumbers CLOSE ordernumbers
使用游标数据
将数据检索到一个o的局部声明的变量中
1 2 3 4 5 6 7 8 9 10 11 12 13 14
CREATEPROCEDURE processorders() BEGIN DECLARE o INT; DECLARE ordernumbers CURSOR FOR SELECT order_num FROM orders; OPEN ordernumbers; FETCH ordernumbers INTO o; CLOSE ordernumbers; END;
或
1 2 3 4 5
... REPEAT FETCH ordernumbers INTO o; UNTIL done ENDREPEAT; ...