MySQL基础
并发控制
读写锁
- 共享锁(读锁):相互不阻塞,多个客户可以同时读取一个资源
- 排他锁(写锁):写锁会 阻塞其他的写锁和读锁
锁粒度
表锁
最基本的锁策略,开销最小。
锁定整张表,用户对表进行写操作前要先获得写锁,会阻塞其他用户的所有读写操作
行级锁
可以最大程度地支持并发处理,但也是锁开销最大的
事务
ACID
- 原子性:一个事务为不可分割的最小单元,要不全部执行,要不全部回滚,不可只执行一部分
- 一致性:数据库总是从一个一致性的状态转到另一个一致性的状态
- 隔离性:一个事务的修改在最终提交前对其他事务是不可见的
- 持久性:一旦事务提交,其所作的修改就永久保存到数据库中
隔离级别
- 未提交读(READ UNCOMMITTED):即使没有提交,对其他事务也是可见的,存在脏读问题
- 提交读(READ COMMITTED)(不可重复读):只能看见已经提交的事务所做的修改,同一事务中多次读取同样记录的结果可能是不同的
- 可重复读(REPEARABLE READ):同一事务中多次读取同样记录的结果是相同的,存在幻读问题
- 可串行化(SERIALIZALE):强制事务串行执行
数据库和数据类型优化
数据类型的优化
数据类型选择原则
- 更小的通常更好
- 简单数据类型更好:整形比字符简单
- 尽量避免NULL:包含NULL得列更难优化,因为索引、索引统计和值比较都更复杂
- 时间:TIMESTAMP占的存储空间比DATATIME小得多
整数类型
TINYINT、SMALLINT\MEDIUMINT、INT、BIGINT分别用8、16、32、64位存储空间,范围从-2^(N-1) 到 2^(N-1),N为位数
如果有UNSIGNED,不允许负值,可以使正数上限提高一倍
指定宽度对于存储和计算没有意义,只是规定交互工具显示的位数
实数
FLOAT、DOUBLE使用浮点计算(近似计算)
DECIMAL存储更精确的小数,但运算比浮点运算慢。数字会打包到二进制字符串中,每4个字节存储9个数字,小数点本身占一个字节
数据量较大时可以用BIGINT代替DECIMAL,乘以相应的倍数
字符串类型
VACHAR
存储变长字符串,需要用1或2个额外字节记录长度
UPDATE时可能使行变得比原来更长,使得页内没有更多空间可以存储。可能会拆成不同片段或者分裂页来解决,视存储引擎而定
适合的情况:字符串的最大长度远大于平均长度;列的更新很少,碎片不是问题
CHAR
会自动删除所有末尾空格
定长,适合长度一定,经常变更的值
BLOB和TEXT
太大时会使用外部存储区域来存储,在行内需要1-4个字节来存储指针
排序时只对最前面的max_sort_length字节做排序
日期和时间
DATETIME能保存大范围的值,从1001年到9999年,精度为秒,YYYYMMDDHHMMSS,用8个字节的空间
TIMESTAMP的范围从1970年到2038年,只用4个字节的存储空间
位数据类型
BIT
在一个列中存储一个或多个true/false,BIT(N)代表几位,最大64
但因为存在取值之后需要转化的问题尽量少使用
SET
可以存储多个true/false,有FIND_IN_SET()等函数,但是改变列的定义的代价较高
标识列的选择
- 整数类型:最好的选择,速度快,可以使用AUTO_INCREMENT
- 字符串类型:消耗空间,计算慢;随机生成的值可能分布在很大空间内,使INSERT和一些SELECT语句变得很慢
特殊类型数据
可使用无符号整数来存储IP地址,INET_ATON()和INET_NTOA()可以进行转换
设计缺陷
- 过多的列:从编码过的列转换成行数据结构的操作代价高
- 过多的关联
- 过度使用枚举
- 变相的枚举:set(‘Y’, ’N‘) 应该用枚举代替,两种情况并不会同时出现
- 过多使用NULL:用表示为空的数值代替NULL
范式和反范式
范式
优点
- 更新操作比反范式快
- 很少或者没有重复数据
- 表通常较小,可以很好地放在内存中,操作更快
- 查询时很少需要DISTINCT和GROUP BY语句(因为重复数据少)
缺点:通常需要关联
反范式
优点:避免关联
数据比内存大的时候扫全表比关联快,因为避免了随机IO
能使用更有效的索引策略:查找付费用户最近的10条信息,可以用索引代替关联查询
缓存表和汇总表
缓存表
可以简单的从数据库其他表获取但速度较慢的表
汇总表
使用GROUP BY语句聚合数据的表
如计算24小时内发送的消息数:以每小时汇总表为基础,把前23个小时的计数加起来,再 加上开始阶段和结束阶段的不完全小时的计数
影子表
重建表时保证数据在操作时仍可以使用:完成建表操作后通过一个原子重命名操作切换影子表和原表
计数器表
若只有一行数据,会导致事务只能串行执行
将表增加100行数据,再选择随机的槽进行更新,获取结果时使用聚合查询
高性能索引
索引类型
B+树索引
数据结构
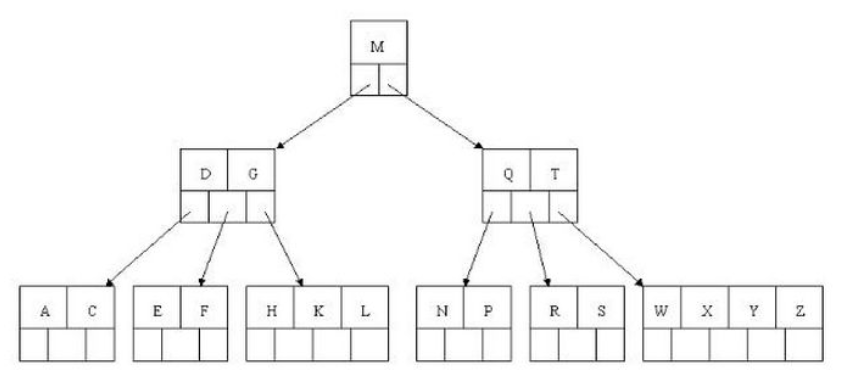
B+树索引适用于全键值、键值范围和键前缀查找,键前缀查找只适用于最左前缀的查找
限制
- 如果不是按照索引的最左列开始查找,则无法使用索引
- 不能跳过索引中的列
- 如果查询中有某个列的范围查询,则右边所有的列都无法使用索引优化查找
联合索引
数据结构
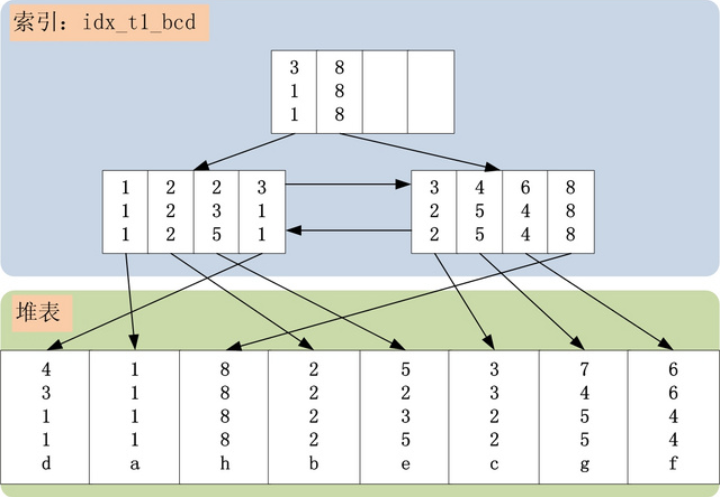
哈希索引
只有精确匹配索引所有列的查询才有效
索引存储对应的哈希值和行指针,结构十分紧凑,查找速度很快;关联很多查找表时哈希索引很适合
限制:
- 不能使用索引中的值来避免读取行(哈希值没有意义)
- 无法用于排序
- 不支持部分索引匹配查找:索引(A,B)无法用于查询A
- 只支持等值查询
- 出现哈希冲突时必须遍历链表中的行指针,逐行比较
- 冲突越多,索引维护操作的代价更高
对于较长的字符串列,可以手动计算哈希来模拟哈希函数,但这么做时不要使用SHA1()和MD5()作为哈希函数,因为其计算结构是长字符串,设计目标为最大限度消除冲突
空间数据索引(R树)
无需前缀索引,会从所有维度来索引数据
全文索引
查找文本中的关键词,并非直接比较数据
索引的优点
- 减少服务器扫描的数据量
- 帮助服务器避免排序和临时表
- 可以将随机I/O变为顺序I/O
表较小时,大部分情况下扫全表更高效
高性能索引策略
独立的列
索引不能是表达式的一部分或函数的参数,必须将索引列单独放在比较符号的一侧
1 | SELECT actor_id FROM actor WHERE actor_id + 1 = 5; |
前缀索引和索引选择性
对于较长的字符串列可以索引开始部分的字符,节约索引空间,提高索引效率,但是会降低选择性
对于BLOB、TEXT或很长的VARCHAR的列,必须使用前缀索引
要选择长度合适的前缀
缺点:MySQL无法用前缀索引做ORDER BY和GROUP BY,也无法用前缀索引做覆盖扫描
多列索引
- 多个索引做相交操作时(AND),需要一个包含所有相关列的多列索引
- 多个索引做联合操作时(OR),需要消耗大量的资源,特别是当有些索引的选择性不高时
选择合适的索引列顺序
将选择性最高的列放在最前列,但是要结合实际情况分析
聚簇索引
当表有聚簇索引时,数据行放在索引的叶子页中,一个表只能有一个聚簇索引,其他索引的值为行的主键值
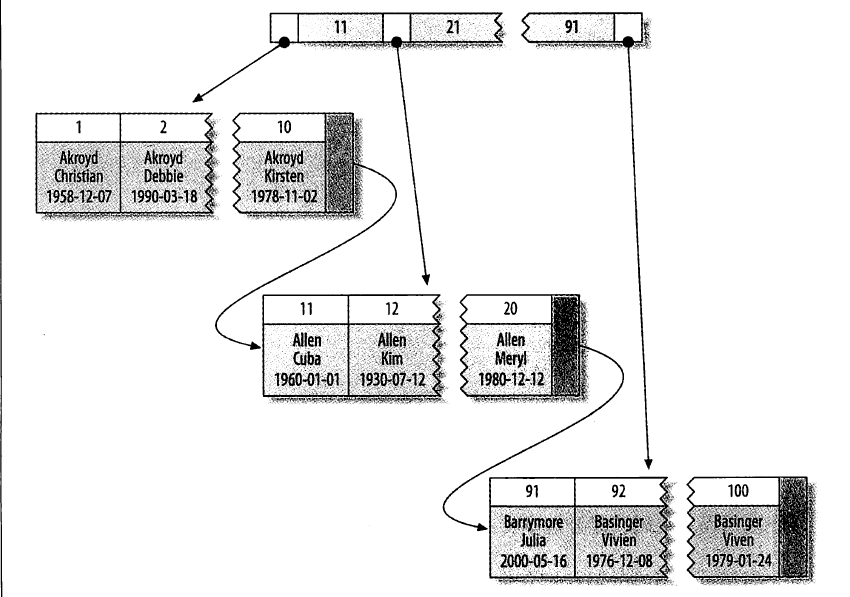
优点:
- 可以把相关数据保存在一起,只需要从磁盘读取少量数据页就能获取某个用户的全部邮件
- 数据访问更快,索引和数据保存在同一颗B+树中
- 覆盖索引扫描的查询可以直接用页节点中的主键值
缺点:
- 如果数据在内存中,访问的顺序不那么重要,就没什么优势了
- 插入速度严重依赖于插入顺序
- 更新聚簇索引列的代价很高
- 插入新行时可能面临页分裂的问题
- 可能导致扫全表变慢,尤其是行比较稀疏,或由于页分裂导致数据存储不连续时
- 二级索引比较大,其叶节点包含了引用行的主键列
- 二级索引需要两次索引查找
InnoDB和MyISAM的数据分布对比
MyISAM按数据插入的顺序存储在磁盘上
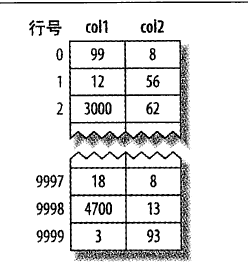
索引分布,主键和其他键相同
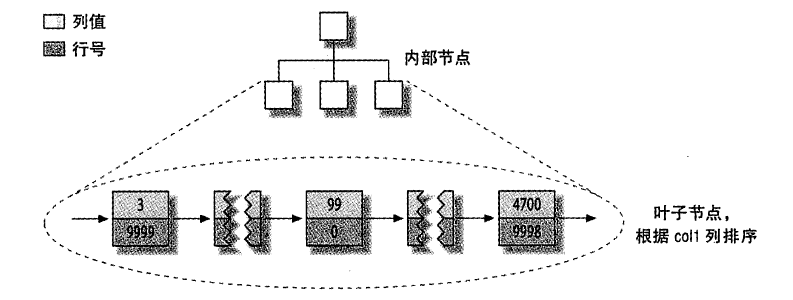
InnoDB的数据分布:叶子节点存储所有数据
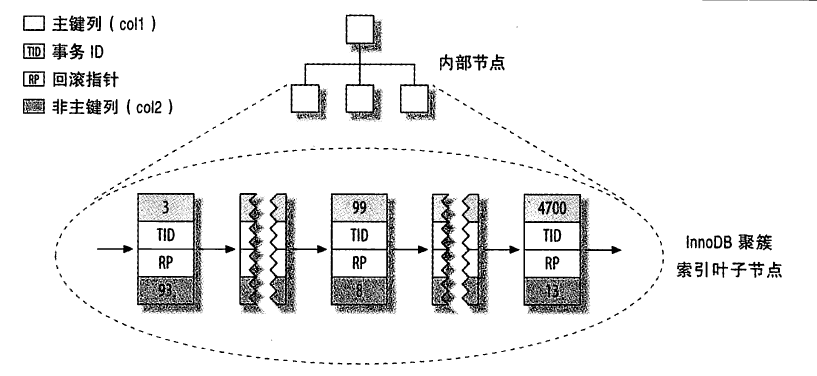
InnoDB的二级索引分布
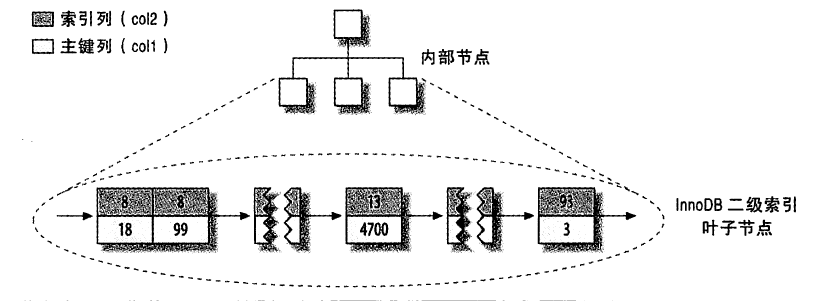
MySIAM二级索引的叶子节点存储行指针,InnoDB存储主键值
聚簇和非聚簇表对比
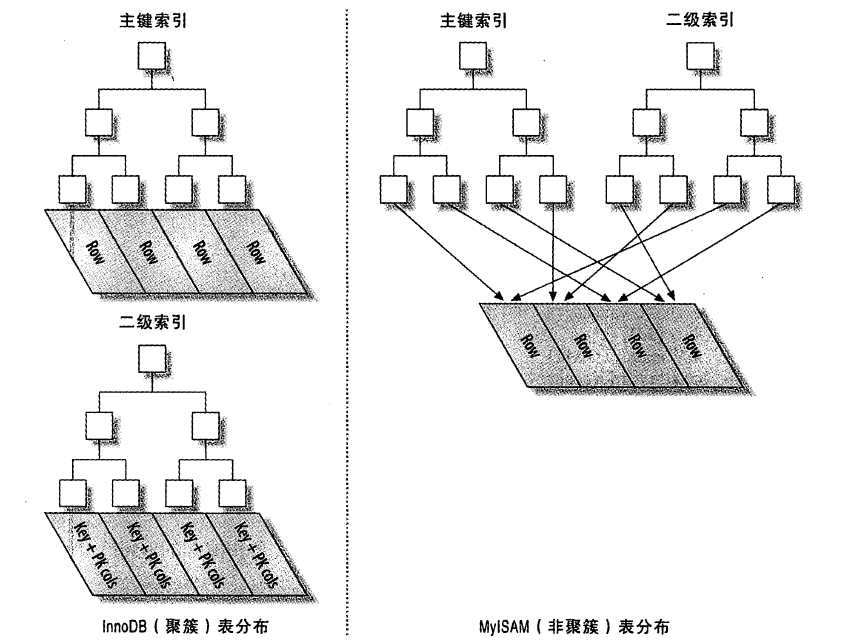
InnoDB的插入
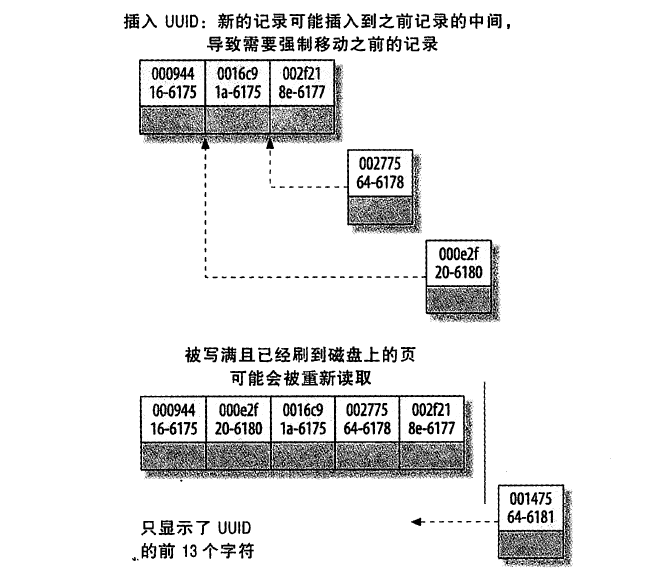
使用InnoDB时应尽可能地按主键顺序插入数据,并且尽可能使用单调增加的聚簇键的值来插入新行。最好避免随机的(不连续且分布范围大)聚簇索引,可以使用自增列作为主键保证按顺序写入。否则:
- 写入的目标可能刷到磁盘上并从缓存移除,插入前不得不从磁盘找到并读取目标页到内存中,导致大量随机I/O
- 频繁页分裂,移动大量数据;页变得稀疏,被不规则填充,数据会有碎片
覆盖索引
一个索引包含所有需要查询的字段的值
优点:
- 索引条目通常少于数据航,减少数据访问量
- 所以按列值顺序存储,范围查询比从磁盘读取每一行I/O少得多
- 对于InnoDB的聚簇索引,若二级逐渐能覆盖查询,可以避免对主键索引的二次查询
不是所有类型的索引都可以做覆盖索引:必须存储索引列的值,哈希、空间、全文索引不可以
使用索引扫描来做排序
只有当索引的列顺序和ORDER BY子句的顺序和排列方向完全一致时才能用索引来对结果排序;若查询需要关联多张表,当ORDER BY子句引用的字段全部为第一个表时才能用索引进行排序
冗余和重复索引
(A,B)和(A)为冗余索引,因为(A,B)可以被当作(A)用
(A,B)和(B,A)不是冗余索引,因为B不是最左前缀
不同类型的索引也不是B+树索引的冗余索引
索引和锁
InnoDB访问行时会对其加锁,索引能减少其访问的行数,从而减少锁的数量
InnoDB有可能无法再服务端过滤掉行后就释放锁,而必须等到适当的时候
1 | SELECT actor_id FROM actor WHERE actor_id < 5 AND actor_id <> 1 FORUPDATE; |
此时锁住了第1-4行,即使第1行不在结果中
即使使用索引也可能锁住不需要的数据,不使用索引可能更糟糕:锁全表
索引案例
技巧
- 当某个查询不限制性别时,可以在查询条件中新增AND SEX IN(‘m’, ‘f’)来访MySQL选择该索引,匹配最左前缀
- 尽可能将范围查询(age)放在最后,以便优化器使用尽可能多的索引列
- IN(a,b,c…)条件如果太多,优化器要做的组合会指数增长
优化排序
通过覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的行,减少MySQL扫描那些要丢弃的行数

索引和数据碎片
数据碎片类型
- 行碎片:数据行被存储在多个地方的多个片段中,即使只访问一行记录性能也会下降
- 行间碎片:逻辑上顺序的页或行,在磁盘上不是顺序存储的。影响全表扫描和基础索引扫描等
- 剩余空间碎片:数据页中有大量空余空间,导致服务器读取大量不需要的数据
MyISAM表三种碎片化都可能发生;InnoDB不会出现短小的行碎片,会移动短小的行并重写到一个片段中
三个原则
- 单行访问是很慢的
- 按顺序访问范围数据是很快的:
- 顺序I/O不需要多次磁盘寻道,比随机I/O要快很多
- 如果要顺序读取数据,不需要额外的排序操作
- 索引覆盖查询是很快的
查询性能优化
优化数据访问
分析步骤:
- 确认应用程序是否检索大量超过需要的数据:访问太多的行或访问太多的列
- 确认MySQL服务器是否分析大量超过需要的数据行
是否向数据库请求了不需要的数据
查询不需要的记录:查询100条,返回10条;应该使用LIMIT
多表关联时返回全部列
- 总是取出全部列
- 重复查询相同数据
MySQL是否扫描额外的记录
衡量指标:响应时间、扫描行数、返回的行数
若需扫描大量数据但返回少数行,可采取的优化方式:
- 使用索引覆盖扫描,无需回表取对应行即可返回结果
- 改变库表结构,如使用单独的汇总表
- 重写复杂查询
重构查询的方式
切分查询
使用一个大语句一次性完成可能需要一次锁住多个数据,占用大量资源
分解关联查询
- 缓存效率更高:若之前查询中行已经被缓存,之后的查询就可以减少一些查询行数
- 减少锁的竞争
- 减少冗余查询,在应用层做关联意味着对某条记录应用只需要查询一次,在数据层做可能要重复访问一部分数据
查询执行的基础
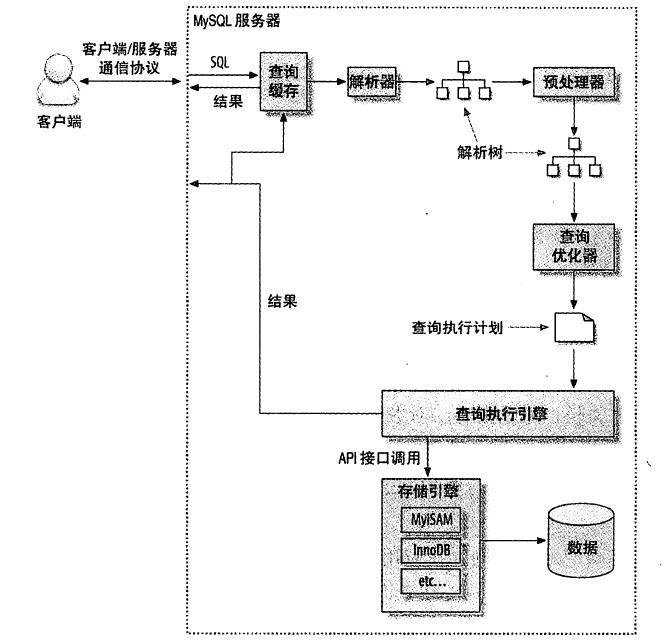
客户端/服务器通信协议
半双工:某个时刻要么是服务器向客户端发数据,要么是客户端向服务器发数据
无流量控制,必须完整接受结果后才响应
查询缓存
对一个大小写敏感的哈希查找实现。即使查询和缓存只有一个字节不同,也不会匹配缓存结果
若命中查询缓存,返回查询结果之前会检查一次用户权限,没问题则跳过所有其他阶段,查询不会被解析不生成执行计划不被执行
查询优化处理
将一个SQL转换成一个执行计划,MySQL依照这个执行计划与存储引擎交互:解析SQL、预处理、优化SQL执行计划
语法解析器和预处理
解析语句,生成解析树并检查是否合法
查询优化器
预测执行计划的成本并选择最小的一个。评估成本时不考虑任何层面的缓存,假设读取任何数据都需要一次磁盘I/O
优化策略:
- 静态优化:只需做一次
- 动态优化:每次执行时都重新评估
优化类型:重新定义关联表的顺序、外连接转内连接、等价变换、优化计数函数、子查询优化、覆盖索引扫描、提前终止查询(使用LIMIT时)…
IN()中有大量取值时,会先排序再进行二分查找,比等价的OR查询速度快
MySQL的关联查询
先将一系列单个查询的结果放入一个临时表中,再读出临时表数据来完成查询
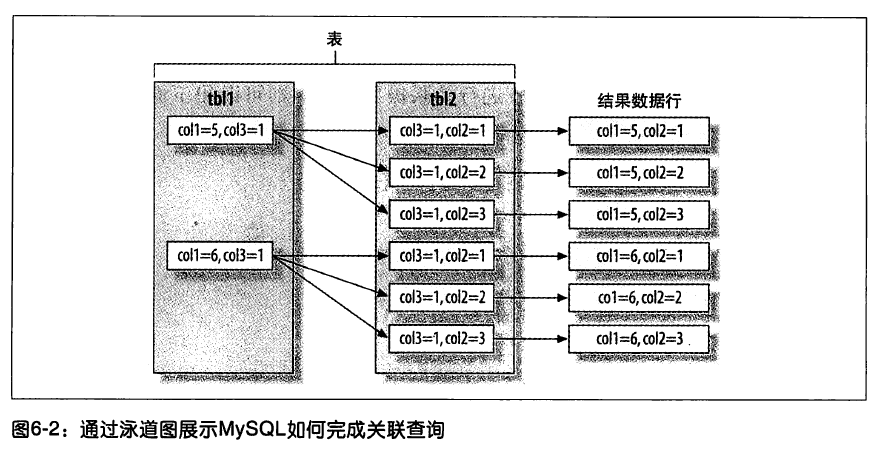
FROM中有子查询时,先执行子查询并将其结果放到一个临时表中
执行计划
生成一棵指令树,通过存储引擎执行完成这棵指令树并返回结果
总是左侧深度优先的树
关联优化器
优化多表关联的顺序,会在所有的关联顺序中选择一个成本最小的来执行
执行计划的搜索空间过大时,使用贪婪的方法优化
排序优化
排序数据量小于缓冲区时,使用内存快速排序
内存不够排序时,将数据分块,对每个独立的块使用快速排序进行排序,合并并返回结果
查询执行引擎,返回结果给客户端
MySQL查询优化器的局限性
关联子查询
MySQL的关联子查询很糟糕,特别是WHERE条件中包含IN()的子查询语句
松散索引扫描
目前MySQL还不支持
对于语句
1 | SELECT ... FROM tbl WHERE b BETWEEN 2 AND 3 |
扫全表
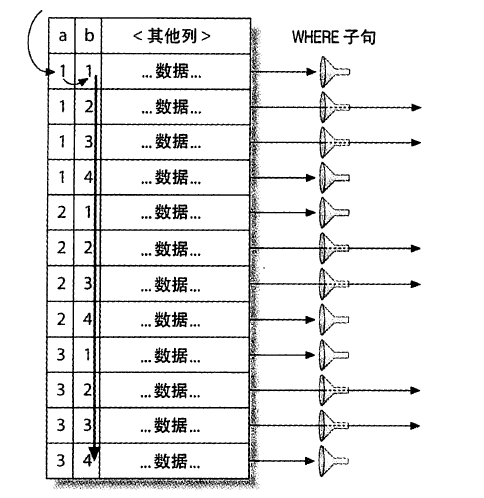
松散索引扫描
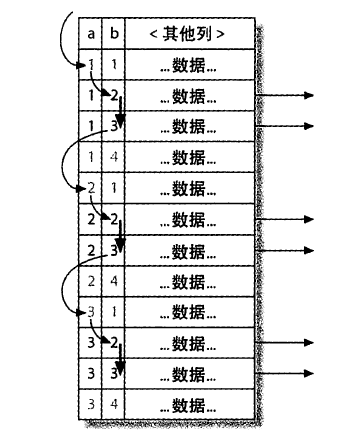
优化特定类型的查询
COUNT()
统计列值:要求列值非空(不为NULL)
统计行数:COUNT(*)时,不会扩展成所有的列,而是直接统计行数
优化LIMIT 分页
如果偏移量很大时,可能需要查询大量的记录再返回很少量的记录,代价巨大
优化方法
- 尽可能用索引覆盖扫描
- 将LIMIT转为已知位置的存储:WHERE position BETWEEN 50 AND 54 ORDER BY position