监控
术语
白盒监控:依靠系统内部的性能指标进行监控
完全依赖白盒监控意味着不知道最终用户看到的是什么样的
黑盒监控:测试外部用户可见的系统行为进行监控
dashboard 监控台页面
监控系统的目标
- 什么东西出故障了
- 为什么出故障(故障出在哪里
4个黄金指标
延迟
流量
QPS、网络 I/O 速率、并发会话数量…
错误
包括显式失败(500)和隐式失败(200中包含了错误内容)
饱和度
延迟增加是饱和度的前导条件
长尾问题
少部分请求占用大量时间导致平均数、中位数无法判断情况——将请求按延迟分组计数(制作直方图),将直方图的边界定义为指数型增长
监控系统的原则
- 最能反映真实故障的规则应该越简单越好
- 不常用的数据收集、告警配置应该定时删除
- 收集到但是没有传给监控台或告警规则的应该定时删除
故障排查
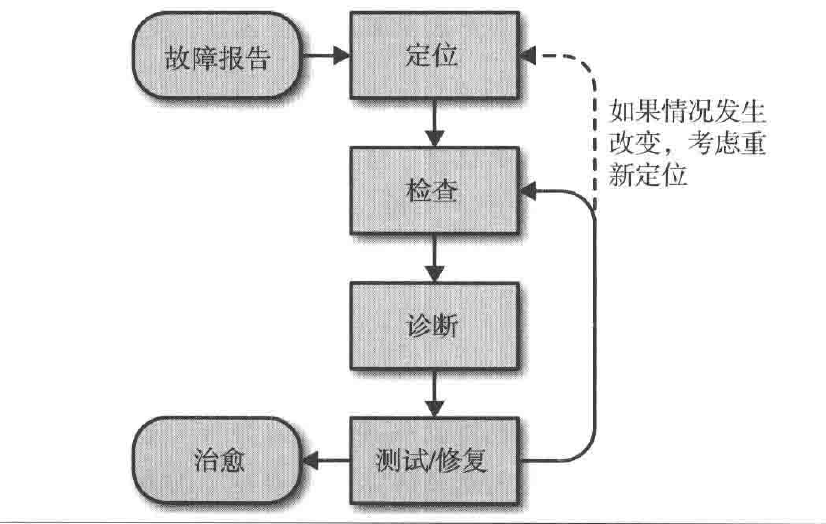
日志和监控图标是确定问题根源的两个工具
测试和恢复
- 理想的测试应该具有互斥性
- 先测试最可能的情况:按照可能发生的顺序测试
- 测试可能产生有误导性的结果
- 测试可能有副作用
- 测试可能无法得出准确的结论
告警
告警粒度和频率
紧急警报太频繁会让人怀疑其有效性甚至忽略
多个报警可以被合并为一个,聚合成一个单独的故障能够减少报警信息的总数
告警方式
- 工单
- 紧急警报
- …